MedBench 最新榜单出炉!润达医疗联合华为揽获评测双冠
5 月 6 日,医疗大模型评测平台 MedBench 发布新版评测榜单,润达医疗与华为基于华为云盘古大模型创新研发的润医医疗大模型以 92.9 分在自测榜单中拔得头筹,在专业评测榜单中以 85.2 分荣膺桂冠。润医医疗大模型在医学语言理解、医学安全和伦理等核心测评维度中表现突出。
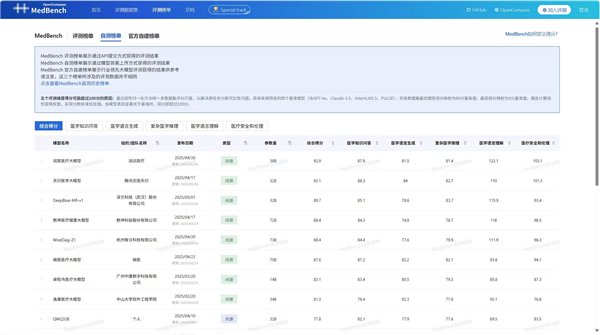
最新版 MedBench 榜单(2025 年 2 月版)
MedBench 作为中文医疗大模型权威评测平台,由上海人工智能实验室、上海市数字医学创新中心联合多家机构打造,已成为全球医疗 AI 领域重要参照标准之一。目前,平台已累计评测全球 387 个医疗大模型,从医学语言理解、生成、知识问答、复杂推理及医疗安全伦理五大维度,提供客观科学的性能评估。
润医医疗大模型能够一举斩获双料第一,甚至在自测榜单中,医学语言理解、医疗安全和伦理维度分别斩获 122.1、103.1 高分,及在专业评测榜中,医学语言理解维度斩获 119.7 高分,充分佐证了润达医疗在医疗大模型研发领域深厚的技术积累与强大的创新硬实力。此外,在医学复杂推理等高阶复杂医疗场景中,模型也取得了领先的效果,凸显了模型运用医学知识进行复杂分析和严谨推理的能力,将在医学辅助诊疗、提升医疗效率和准确率等方面发挥重要作用。
多维能力突出重构人机协同范式
润医医疗大模型在华为云盘古大模型 L0 层的基础上,训练使用了千亿级高质量的中英文医学文献、医学指南、书籍,及千万量级医疗健康档案和知识图谱等数据,融合高质量通用数据,构成了润医医疗大模型底座。
从技术特性来看,380 亿高参数量赋予模型强大的学习能力,使其能够精准捕捉医疗数据中的复杂模式与内在关系,显著提升语言理解和生成能力,足以胜任各类复杂医疗任务。而支持 32k 序列长度,则确保模型具备卓越的长文本处理能力,能够充分理解上下文语义,极大增强对复杂医疗文本的分析解读效能,可在多轮对话、复杂病例分析等应用场景中优势明显。作为大模型训练的核心要素,海量高质量数据为模型提供了丰富且准确的知识来源,可有效提升模型泛化能力,使其在各类实际医疗场景中能够做出更精准的判断与决策。
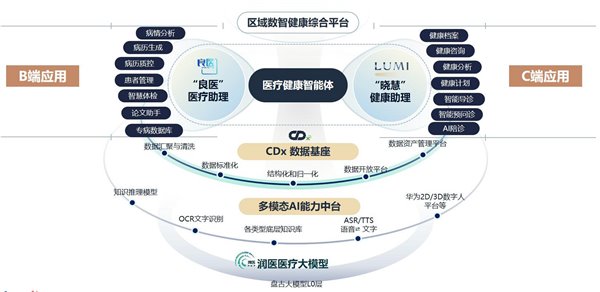
基于模型底座,润达医疗还创新研发了循证推理引擎,通过构建“动态权重分配、证据链追溯与不确定性量化”的“三位一体”临床决策系统。其中,动态权重分配确保了模型可实时聚焦关键医学信息;证据链追溯则通过知识图谱,能够验证推理路径;不确定性量化则对模糊信息进行概率评估。三项创新机制的协同运作,有效将模型幻觉率严格控制了在医疗级安全阈值内。不仅如此,润达医疗还打造具有双向进化机制的可信 AI 大脑,在服务医生的过程中持续学习临床反馈,反向优化自身推理路径,重构人机协同范式,让 AI 成为医生智慧的延伸,更精准地满足医生和患者的知识需求,真正成为医疗场景中可靠的智能助手。
得益于多项核心创新技术的有力支撑,润医医疗大模型在 MedBench 评测的多个维度中均展现卓越性能,尤其是语言理解与医疗安全和伦理维度。在医学语言理解上,动态权重分配、证据链追溯与不确定性量化机制协同,可精准捕捉文本关键信息与逻辑。而在医疗安全与伦理维度,“循证推理 + 可信 AI”架构深度剖析复杂场景,严格审查伦理风险,为医疗质效提升与合规安全筑牢双重保障。
真实场景验证赋能医疗质效革新
从技术突破到民生福祉,润达医疗基于大模型和数据治理的智慧医疗解决方案,贯穿“防-治-管”全流程,提供覆盖疾病预防、诊断治疗、患者管理的全生命周期服务,已在智慧检验、病情分析、病历生成与质控、区域健康管理等多维度真实医疗场景中完成实践验证,成功实现智慧诊疗全场景落地应用。
基于润医医疗大模型,润达医疗与美年健康共同孵化的国内首款 AI 私人健康管理师“健康小美”,截至今年 3 月底,其智能主检应用已在美年健康 109 家体检中心上线应用,且审核并生成超 39 万份体检报告,重点指标精准率 90%+。