中国团队推出脑电图图像生成模型 DreamDiffusion,清华、腾讯参与研究
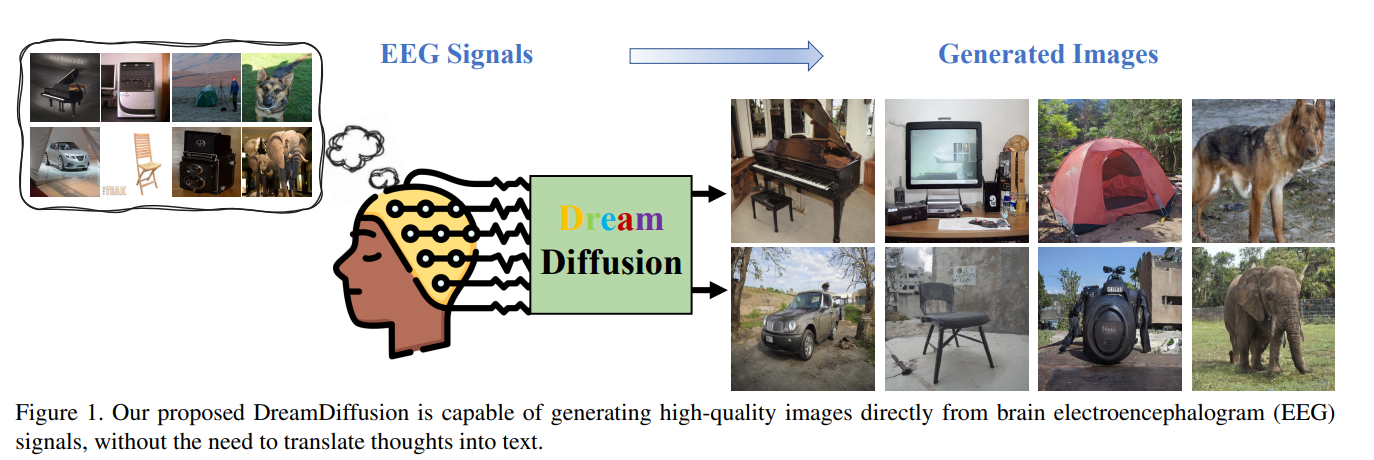
IT酷哥 7 月 5 日消息,清华大学深圳国际研究生院、腾讯人工智能实验室(AI Lab)和鹏城实验室的研究人员近日发表论文称,研究团队开发了一个名为 DreamDiffusion 的图像生成模型,该模型可以直接通过脑电图(EEG)信号生成高质量图像。相关论文发表于美国康奈尔大学旗下在线学术论文平台 arXiv 上。
目前已有不少团队研究了使用文本到图像的扩散模型从人脑生成图像的方法,但大多数采用的都是功能性磁共振成像(fMRI)技术捕捉大脑活动从而生成图像。这种技术缺乏实用性,因为它需要专家操作并且需要昂贵且难以携带的 fMRI 设备。
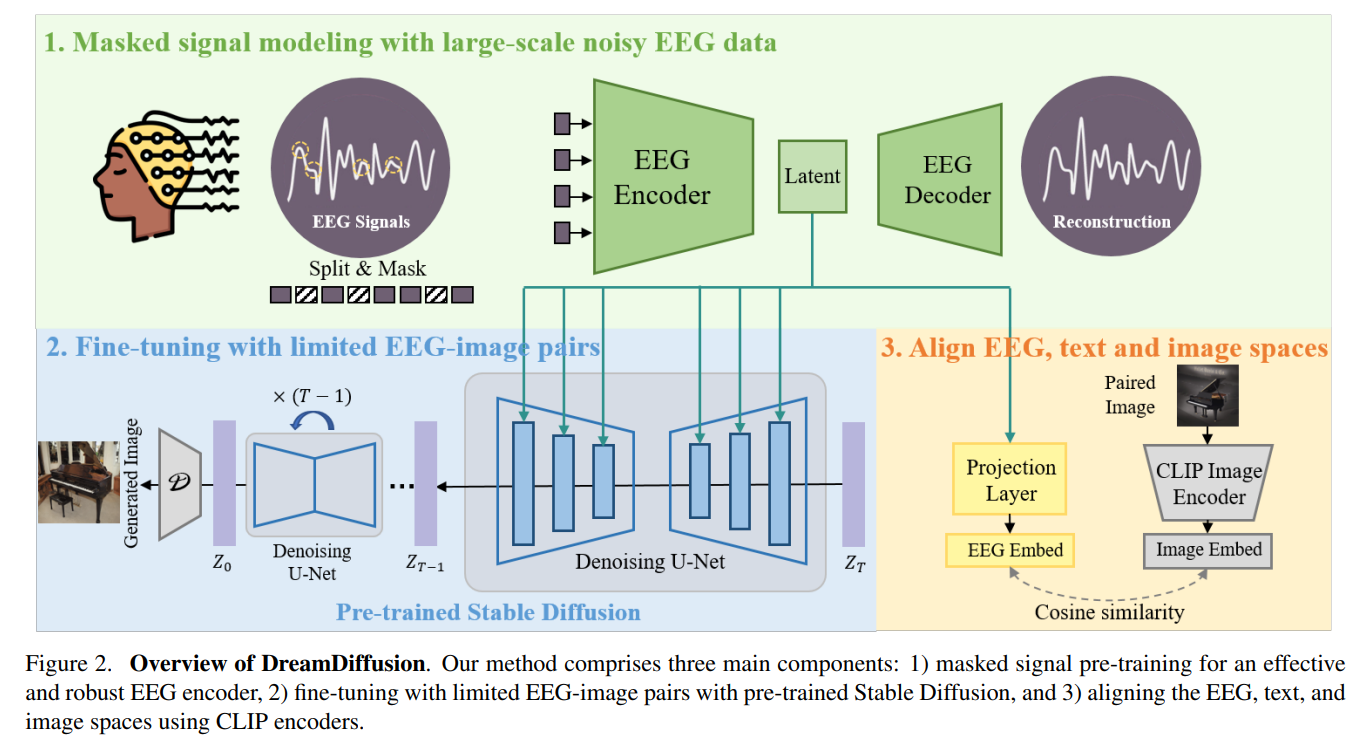
相比之下,脑电图是一种记录大脑电波活动的非侵入性、低成本方法,且已有一些便携式商业产品可以轻松采集脑电图信号。于是,研究团队提出了一种“稳定扩散”的图像生成方法,能够减少脑电图信号的噪声干预,使扩散模型的预训练更稳定有效。
研究团队向 6 位受试者展示了属于 40 个不同对象类别的 2000 张图像,进而通过采集受试者的脑电图信号来生成高质量图像。下图中每组左边标有 GT 的是原始图像,右边的 Sample 图像为脑电图生成图像。

为了评估该方法的准确性,研究团队将其与最近的另一项类似研究 Brain2Image 进行了定性比较,结果证实,其准确率明显高于 Brain2Image 生成的图像,从而证明了该方法的有效性。

IT酷哥附上论文地址:点此前往